
搜索到
4
篇与
的结果
-
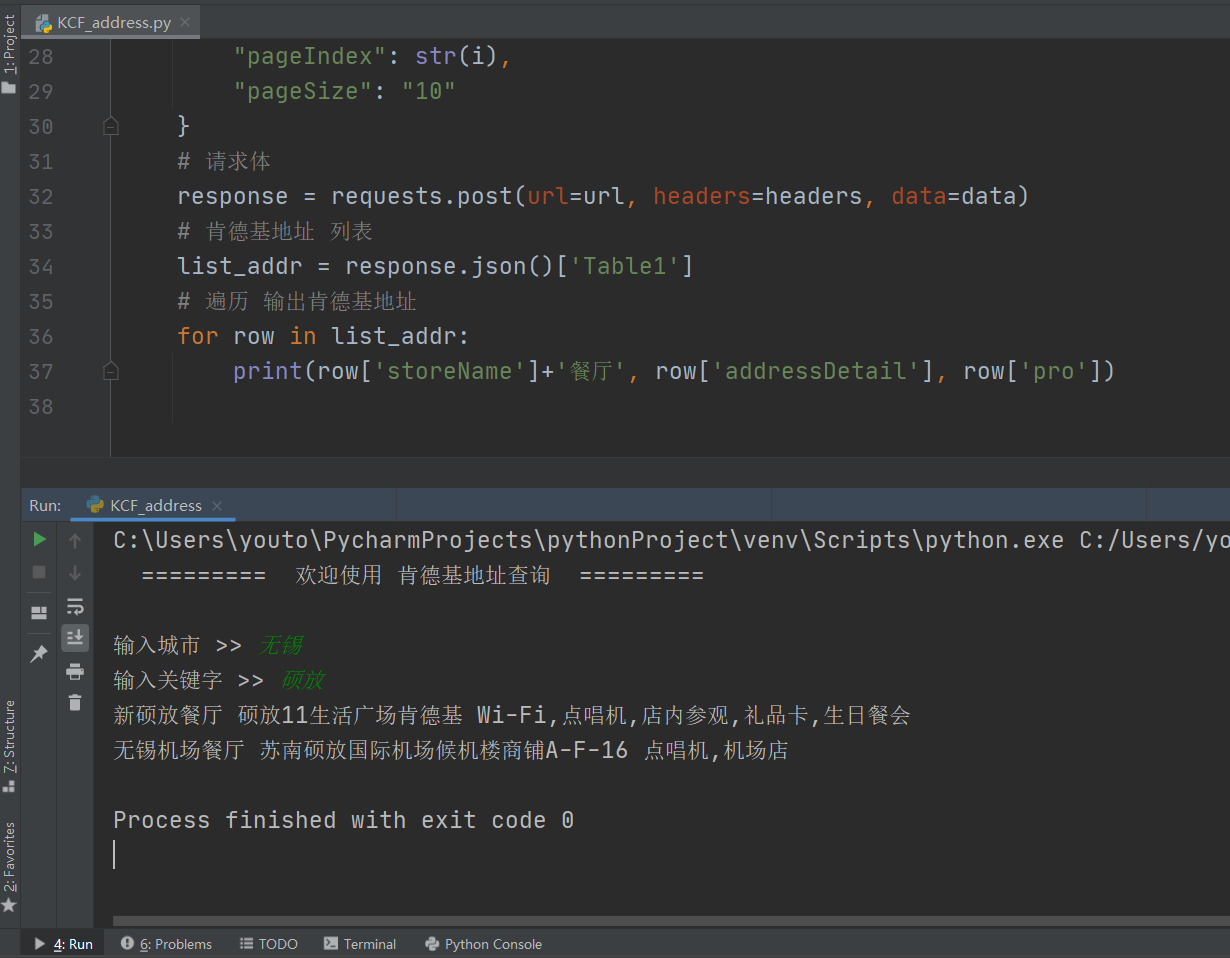
 爬取肯德基地址 简单获取肯德基地址 """ 作者:Acha 时间:2021-2-15 功能:查询肯德基地址信息 """ import requests # 肯德基URL url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 提示进入操作界面 print(" ========= 欢迎使用 肯德基地址查询 =========", '\n') # 请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36"} # 城市,关键字 查询 city = str(input("输入城市 >> ")) keyword = str(input("输入关键字 >> ")) # 查询前 5 页地址 for i in range(5): # 动态参数 data = { "cname": city, "pid": '', "keyword": keyword, "pageIndex": str(i), "pageSize": "10" } # 请求体 response = requests.post(url=url, headers=headers, data=data) # 肯德基地址 列表 list_addr = response.json()['Table1'] # 遍历 输出肯德基地址 for row in list_addr: print(row['storeName']+'餐厅', row['addressDetail'], row['pro'])
爬取肯德基地址 简单获取肯德基地址 """ 作者:Acha 时间:2021-2-15 功能:查询肯德基地址信息 """ import requests # 肯德基URL url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 提示进入操作界面 print(" ========= 欢迎使用 肯德基地址查询 =========", '\n') # 请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36"} # 城市,关键字 查询 city = str(input("输入城市 >> ")) keyword = str(input("输入关键字 >> ")) # 查询前 5 页地址 for i in range(5): # 动态参数 data = { "cname": city, "pid": '', "keyword": keyword, "pageIndex": str(i), "pageSize": "10" } # 请求体 response = requests.post(url=url, headers=headers, data=data) # 肯德基地址 列表 list_addr = response.json()['Table1'] # 遍历 输出肯德基地址 for row in list_addr: print(row['storeName']+'餐厅', row['addressDetail'], row['pro']) -
爬取51job岗位信息 提示:岗位链接的xpath表达式会经常变更 # coding=utf-8 """ 时间:2020/11/13 作者:wz 功能:使用python爬虫爬取51job岗位信息 """ import requests from lxml import etree from urllib import parse import time def get_html(url, encoding='utf-8'): """ 获取每一个 URL 的 html 源码 : param url:网址 : param encoding:网页源码编码方式 : return: html 源码 """ # 定义 headers headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Mobile Safari/537.36'} # 调用 requests 依赖包的get方法,请求该网址,返回 response response = requests.get(url, headers=headers) # 设置 response 字符编码 response.encoding = encoding # 返回 response 的文本 return response.text def crawl_each_job_page(job_url): # 定义一个 job dictionary job = {} # 调用 get_html 方法返回具体的html文本 sub_response = get_html(job_url) # 将 html 文本转换成 html sub_html = etree.HTML(sub_response) # 获取薪资和岗位名称 JOB_NAME = sub_html.xpath('//div[@class="j_info"]/div/p/text()') if len(JOB_NAME) > 1: job['SALARY'] = JOB_NAME[1] job['JOB_NAME'] = JOB_NAME[0] else: job['SALARY'] = '##' job['JOB_NAME'] = JOB_NAME[0] # 获取岗位详情 FUNC = sub_html.xpath('//div[@class="m_bre"]/span/text()') job['AMOUNT'] = FUNC[0] job['LOCATION'] = FUNC[1] job['EXPERIENCE'] = FUNC[2] job['EDUCATION'] = FUNC[3] # 获取公司信息 job['COMPANY_NAME'] = sub_html.xpath('//div[@class="info"]/h3/text()')[0].strip() COMPANY_X = sub_html.xpath('//div[@class="info"]/div/span/text()') if len(COMPANY_X) > 2: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = COMPANY_X[1] job['COMPANY_INDUSTRY'] = COMPANY_X[2] else: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = '##' job['COMPANY_INDUSTRY'] = COMPANY_X[1] # 设置来源 job['FROM'] = '51job' # 获取ID job_url = job_url.split('/')[-1] id = job_url.split('.')[0] job['ID'] = id # 获取岗位描述 DESCRIPTION = sub_html.xpath('//div[@class="c_aox"]/article/p/text()') job['DESCRIPTION'] = "".join(DESCRIPTION) # 打印 爬取内容 print(str(job)) # 将爬取的内容写入到文本中 # f = open('D:/51job.json', 'a+', encoding='utf-8') # f.write(str(job)) # f.write('\n') # f.close() # main 函数启动 if __name__ == '__main__': # 输入关键词 key = 'python' # 编码调整 key = parse.quote(parse.quote(key)) # 提示开始 print('start') # 默认访问前3页 for i in range(1, 4): # 初始网页第(i)页 page = 'https://search.51job.com/list/080200,000000,0000,00,9,99,' + str(key) + ',2,' + str(i) + '.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' # 调用 get_html 方法返回第 i 页的html文本 response = get_html(page) # 使用 lxml 依赖包将文本转换成 html html = etree.HTML(response) # 获取每个岗位的连接列表 sub_urls = html.xpath('//div[@class="list"]/a/@href') # 判断 sub_urls 的长度 if len(sub_urls) == 0: continue # for 循环 sub_urls 每个岗位地址连接 for sub_url in sub_urls: # 调用 crawl_each_job_page 方法,解析每个岗位 crawl_each_job_page(sub_url) # 睡 3 秒 time.sleep(3) # 提示结束 print('end.')
-
模拟登录古诗文网 """ 作者:acha 时间:2021-2-16 功能:模拟登录古诗文网 """ import requests from lxml import etree from 爬虫.chaojiying_Python.chaojiying import Chaojiying_Client # 请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36" } # 创建好session对象 sess = requests.Session() # 处理动态变化的请求参数 # 1.解析出本次登录页面对应的验证码图片地址 login_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx' page_text = sess.get(url=login_url, headers=headers).text tree = etree.HTML(page_text) # 解析出了验证码图片的地址 img_path = 'https://so.gushiwen.org' + tree.xpath('//*[@id="imgCode"]/@src')[0] img_data = sess.get(url=img_path, headers=headers).content # 请求到了图片数据 # 将图片保存到本地存储 with open('./code.jpg', 'wb') as fp: fp.write(img_data) # 将动态变化的请求参数从页面源码中解析出来 __VIEWSTATE = tree.xpath('//*[@id="__VIEWSTATE"]/@value')[0] __VIEWSTATEGENERATOR = tree.xpath('//*[@id="__VIEWSTATEGENERATOR"]/@value')[0] # 识别验证码 def imgcode(file_path): chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') im = open(file_path, 'rb').read() code = (chaojiying.PostPic(im, 1004)['pic_str']) print(code) return code # 获取验证码 code_result = imgcode('code.jpg') # 古诗文网 url post_url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx' # 动态参数 data = { "__VIEWSTATE": "lG3WvIKiDx5sEmj8IeYT6LmF1reN9ep/Q2b+U7W2RCMdA2JF5F9NRvaEfIepywyrCTFVIlRHGtorc6dkttOZ0GCzQsQPFdpLeB2kDD6J+vXb/BvqhxWtwSJ+02I=", "__VIEWSTATEGENERATOR": "C93BE1AE", "from: http": "//so.gushiwen.cn/user/collect.aspx", "email": "wz.0527@qq.com", "pwd": "qwerqwer", "code": code_result, "denglu": "登录", } # 模拟登录的请求 response = sess.post(url=post_url, headers=headers, data=data) # 登录成功后页面的源码数据 page_text = response.text # 保存网页 with open('gushiwen.html', 'w', encoding='utf-8') as fp: fp.write(page_text)
-
查询化妆品许可证信息 """ 作者:acha 时间:2021-2-15 功能:查询化妆品许可证信息 """ import requests # 药监局许可证信息数据列表 URL url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList' # 药监局许可证具体数据列表 URL url_id = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById' # 请求头 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36" } # 获取网页 json 数据 def get_page_text(c_url, c_data): # 请求体 resqonse = requests.post(url=c_url, headers=headers, data=c_data) # 获取数据 page_text = resqonse.json() # 返回数据 json return page_text for i in range(10): # 动态参数 需要处理变量 页码 data = { "on": " true", "page": str(i), "pageSize": " 15", "productName": " ", "conditionType": "1", "applyname": " ", "applysn": " " } # 获取 企业id page_id = get_page_text(url, data) # 生成 id 列表 lst_id = page_id['list'] # 输出 页面码 print(data['page']) # 遍历 id列表 返回许可证详细信息 for row in lst_id: # 动态参数 企业id data_id = {'id': row['ID']} # 获取许可证详细 result = get_page_text(url_id, data_id) # 打印获取信息 print(result)