

提示:岗位链接的xpath表达式会经常变更
# coding=utf-8
"""
时间:2020/11/13
作者:wz
功能:使用python爬虫爬取51job岗位信息
"""
import requests
from lxml import etree
from urllib import parse
import time
def get_html(url, encoding='utf-8'):
"""
获取每一个 URL 的 html 源码
: param url:网址
: param encoding:网页源码编码方式
: return: html 源码
"""
# 定义 headers
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Mobile Safari/537.36'}
# 调用 requests 依赖包的get方法,请求该网址,返回 response
response = requests.get(url, headers=headers)
# 设置 response 字符编码
response.encoding = encoding
# 返回 response 的文本
return response.text
def crawl_each_job_page(job_url):
# 定义一个 job dictionary
job = {}
# 调用 get_html 方法返回具体的html文本
sub_response = get_html(job_url)
# 将 html 文本转换成 html
sub_html = etree.HTML(sub_response)
# 获取薪资和岗位名称
JOB_NAME = sub_html.xpath('//div[@class="j_info"]/div/p/text()')
if len(JOB_NAME) > 1:
job['SALARY'] = JOB_NAME[1]
job['JOB_NAME'] = JOB_NAME[0]
else:
job['SALARY'] = '##'
job['JOB_NAME'] = JOB_NAME[0]
# 获取岗位详情
FUNC = sub_html.xpath('//div[@class="m_bre"]/span/text()')
job['AMOUNT'] = FUNC[0]
job['LOCATION'] = FUNC[1]
job['EXPERIENCE'] = FUNC[2]
job['EDUCATION'] = FUNC[3]
# 获取公司信息
job['COMPANY_NAME'] = sub_html.xpath('//div[@class="info"]/h3/text()')[0].strip()
COMPANY_X = sub_html.xpath('//div[@class="info"]/div/span/text()')
if len(COMPANY_X) > 2:
job['COMPANY_NATURE'] = COMPANY_X[0]
job['COMPANY_SCALE'] = COMPANY_X[1]
job['COMPANY_INDUSTRY'] = COMPANY_X[2]
else:
job['COMPANY_NATURE'] = COMPANY_X[0]
job['COMPANY_SCALE'] = '##'
job['COMPANY_INDUSTRY'] = COMPANY_X[1]
# 设置来源
job['FROM'] = '51job'
# 获取ID
job_url = job_url.split('/')[-1]
id = job_url.split('.')[0]
job['ID'] = id
# 获取岗位描述
DESCRIPTION = sub_html.xpath('//div[@class="c_aox"]/article/p/text()')
job['DESCRIPTION'] = "".join(DESCRIPTION)
# 打印 爬取内容
print(str(job))
# 将爬取的内容写入到文本中
# f = open('D:/51job.json', 'a+', encoding='utf-8')
# f.write(str(job))
# f.write('\n')
# f.close()
# main 函数启动
if __name__ == '__main__':
# 输入关键词
key = 'python'
# 编码调整
key = parse.quote(parse.quote(key))
# 提示开始
print('start')
# 默认访问前3页
for i in range(1, 4):
# 初始网页第(i)页
page = 'https://search.51job.com/list/080200,000000,0000,00,9,99,' + str(key) + ',2,' + str(i) + '.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare='
# 调用 get_html 方法返回第 i 页的html文本
response = get_html(page)
# 使用 lxml 依赖包将文本转换成 html
html = etree.HTML(response)
# 获取每个岗位的连接列表
sub_urls = html.xpath('//div[@class="list"]/a/@href')
# 判断 sub_urls 的长度
if len(sub_urls) == 0:
continue
# for 循环 sub_urls 每个岗位地址连接
for sub_url in sub_urls:
# 调用 crawl_each_job_page 方法,解析每个岗位
crawl_each_job_page(sub_url)
# 睡 3 秒
time.sleep(3)
# 提示结束
print('end.')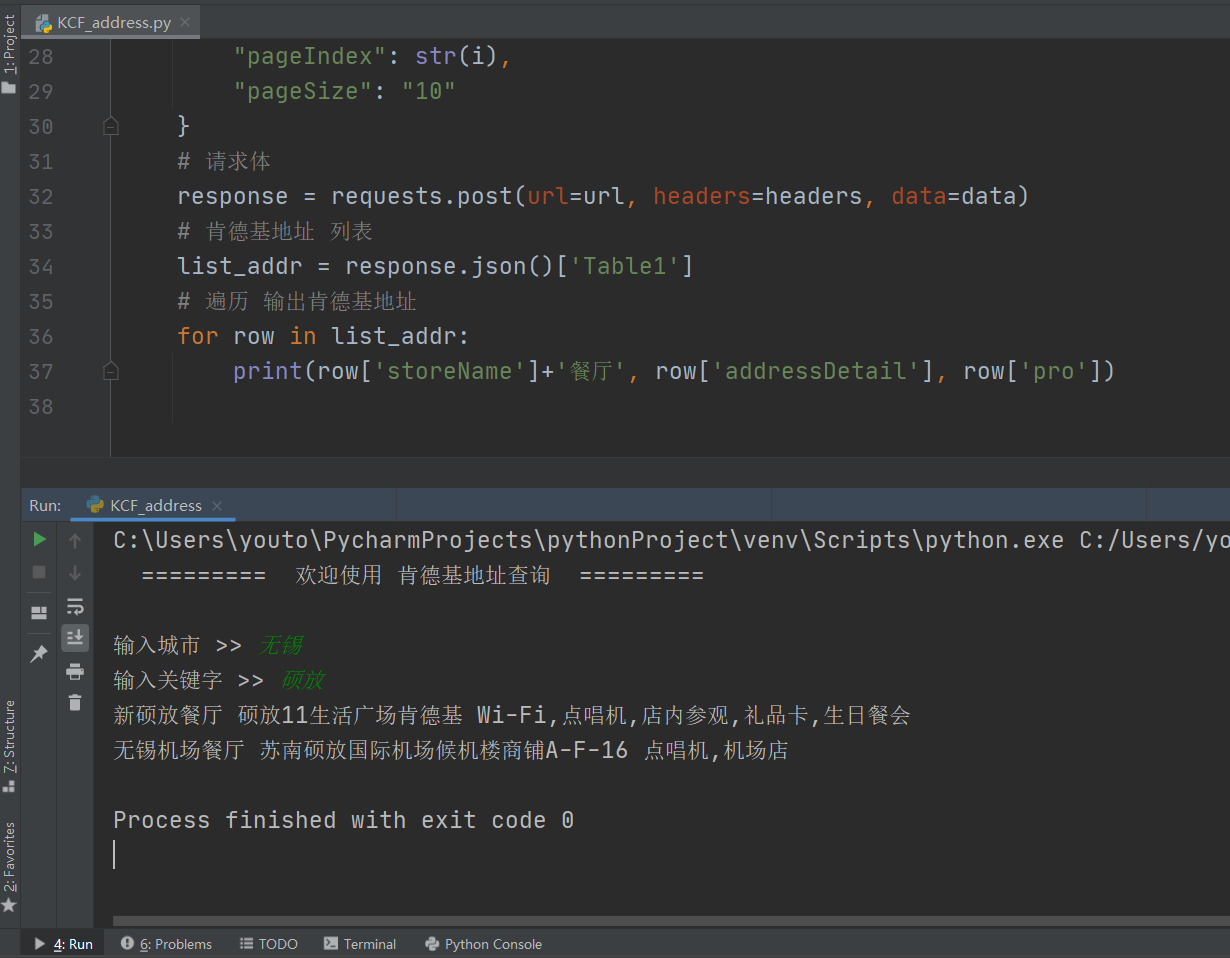


评论